Definitive 7 Point Disaster Recovery Planning Checklist
The need for a comprehensive disaster recovery plan cannot be felt more than in the aftermath of massive hurricanes that recently ravaged the west coast of the US.
Days-long power knockouts, physical blows, and supply chain breakdowns left thousands of businesses in the dark. Most of them are now facing insurance fights and significant infrastructure rebuilds to get back on track.
These are complex challenges that many will struggle to overcome. The organizations that had disaster recovery and business continuity plans in place now have one less thing to worry about.
Designed to enable businesses to reduce damages of unpredicted outages, a disaster plan is a long-term assurance of business operability. While a disaster of this scale is not an everyday scenario, it can be fatal to business operations.
And it can happen to anyone.
In one form or another, natural disasters and human errors are a constant possibility, and this is why it makes sense to prepare for them. When you add different types of cyber-attacks to the mix, the value of a disaster recovery checklist is even more significant.
This is especially true when you take into account that the average cost of downtime can go up to $5600 per minute in mid-sized businesses and up to $11,000 per minute in enterprises.
With every second of outage counting against your profits, avoiding any impact of downtime is a strategic aim. This is best achieved by preparing your entire infrastructure to resist and stay operational even in the harshest situations.
Why You Need Disaster Recovery Plan: Case Study
While the probability of a disaster may often seem hypothetical, some recent events confirmed that hazards are a real thing. And costly, too.
Hurricanes Irma and Harvey are some of the most striking examples, but a lot of other things can go wrong in business and cause disruptions. One of the cases in point took place earlier in May when British Airways suffered a significant infrastructure technology system collapse. The three-day inoperability left thousands of passengers stuck at airports across the world, while the company worked to identify and fix the error to get their critical systems back online. The entire data disaster reportedly cost 500 million pounds to the company, while its reputation is still on the line.
When it comes to business disruptions, it does not get more real than that.
The BA case is yet another unfortunate confirmation of the fact that unplanned outages can take place anytime and in any company. The ones that have no stable disaster recovery and business continuity plans are bound to suffer extreme financial and reputational losses. This is especially the case with those that have complex and globally dispersed IT infrastructures, where 100% availability is paramount.
Events like these call for a discussion on the disaster recovery best practices that may help companies like this avoid any similar collapses in the future. Below is an overview of the critical items that need to be in the data management plan. What is disaster recovery planning?
Learn everything you need to know about backup and disaster recovery (BDR).
1. Risk Assessment and Business Impact Analysis (BIA)
The best way to fight the enemy is to get to know the enemy.
The same goes for disaster recovery planning, where the first step is to identify possible threats and their likelihood to impact your businesses. The outcome of this process is a detailed risk analysis with an overview of some common threats in the context of your business.
Start the disaster recovery planning process with a risk assessment. Develop a risk matrix, where you will classify the types of disasters that can occur. The risk matrix is essential to establish priorities and identify the scope of damage that can be devastating for business.
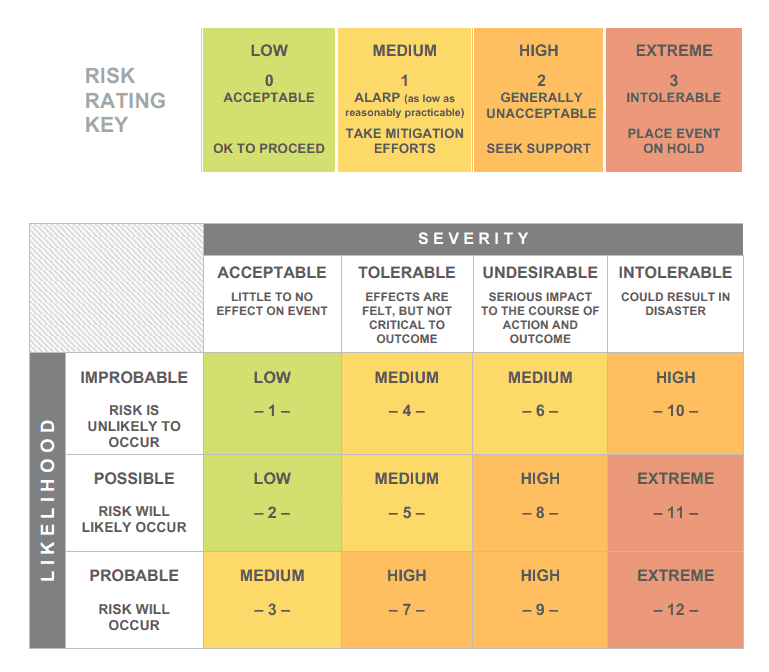
Resource: smartsheet
After you identify and analyze the risks, you can create a business impact analysis (BIA). This document should help you understand the actual effects of any unfortunate event that can hit your business. Whether it is a loss of physical access to premises, system collapse, or inability to access data files, this matrix is a base for planning the next steps.
To get started with BIA, you can use FEMA’s resource with a simple disaster recovery plan template.
2. Recovery Time Objective (RTO) and Recovery Point Objective (RPO)
RTO and RPO are critical concepts in disaster recovery planning, whether your data resides in a dedicated hosting or virtualized environments.
As a reminder, these two refer to the following:
- The amount of time needed to recover all applications (RTO)
- The amount of data loss that you risk losing during disaster recovery, calculated in relation to the amount of time required to complete the process (RPO)
RTO and RPO real-life values will vary between companies. Setting RTO and RPO goals should involve a cross-department conversation to best assess business needs in this respect.
The objectives you define this way are the foundation of an effective disaster recovery plan. They also determine which solutions to deploy. This refers to both hardware and software configurations needed to recover specific workloads.

3. Response Strategy Guidelines and Detailed Procedures
Documenting a written DR plan is the only way to ensure that your team will know what to do and where to start when a disaster happens.
Written guidelines and procedures should cover everything from implementing DR solutions and executing recovery activities to infrastructure monitoring and communications. Additionally, all the relevant details about people, contacts, and facilities should be included to make every step of the process transparent and straightforward.
Some of the general process documents and guidelines to develop include:
- Communication procedures, outlining who is responsible for announcing the disaster and communicating with employees, media, or customers about it;
- Data Backup procedures, with a list of all facilities or third-party solutions used for document backups.
- Guidelines for initiating a response strategy (responsible staff members, outline of critical activities, contact persons, etc.)
- Post-disaster activities that should be carried out after critical apps and services are reestablished (contacting customers, vendors, etc.).
The key to developing effective procedures is to include as many details as possible about every activity. The essential ones are a) name of a responsible person with contact details, b) action items, c) activity timeline, and e) how it should be done. This way, you can achieve full transparency for every critical process in the overall DRP.
If you’re not sure how to start, this Disaster Recovery guide will provide you with relevant details.
4. Disaster Recovery Sites
Putting the plan to work also involves choosing the disaster recovery site where all vital data, applications, and physical assets can be moved in case of a disaster. Such a site needs to support active communications, meaning that they should have both critical hardware and software in place.
Traditionally, three types of sites are used for disaster recovery:
- A hot site, which is defined as a site that allows a “functional data center with hardware and software, personnel and customer data;”
- A warm site that would allow access to all critical applications excluding customer data;
- A cold site, where you can store IT systems and data, but that has no technology until the IT disaster recovery checklist is put into motion.
Most DR solutions automatically backup and replicate critical workloads at multiple sites to strengthen and speed up the recovery process. With the advances in virtualization and replication technologies, DR capabilities that are at the disposal of modern companies are many. Choosing the right one involves finding the balance between price, technology, and a provider’s ability to cater to your own needs.

5. Incident Response Team
When a disaster strikes, all teams get involved. To efficiently carry out a disaster recovery plan, you should name specific people to handle different recovery activities. This is key to ensuring that all the tasks will be completed as efficiently as possible.
The activities of the incident response team will vary, and they should be defined within DR guidelines and procedure documents. Some of these include communicating with employees and external media, monitoring the systems, system setup and recovery operations.
Like with all the other guidelines and procedures, details about incident response team should include:
- The action to complete
- The job role of a person responsible for completing the work
- Name/contact details of a person responsible
- The timeframe in which the activity should be completed
- Steps that more closely describe the operation
The Incident response team will involve multiple departments – from technicians to senior management – each of which may have an essential role in minimizing the effects of a disaster.
6. IT Disaster Recovery Services
Recovering complex IT systems may require massive manpower, hardware resources, and technical knowledge. Many of these can be supplemented by third-party resources and cloud computing solutions. Cloud-based resources are particularly handy to optimize costs and shift parts of the infrastructure to remote servers, which brings higher security and better use of costs.
In companies where not all workloads are suitable for public cloud backup, a balanced distribution between on-site and cloud servers is a cost-effective way to configure infrastructure. Similarly, a hybrid approach to an IT disaster recovery plan is ideal for companies with advanced recovery needs.
A particularly convenient option for businesses of any size is Disaster-Recover-as-a-Service (DRaaS), which offers greater flexibility to teams operating within a limited DR budget. DRaaS allows access to critical infrastructure and backup resources at an affordable price point. It can also be used in both virtualized and dedicated environments, which makes it suitable for companies of any size and any infrastructure need.
Learn how phoenixNAP combines Backup, Disaster-Recover-as-a-Service, and Data Security Cloud with the most comprehensive ransomware protection solutions for your business needs.

7. Maintenance and testing activities
Once created, a disaster recovery plan needs to be reviewed and tested regularly. This is the only way to ensure that it is efficient long-term and that it can be applied in any scenario.
While most modern businesses now have recovery strategies in place, many of them are outdated and not aligned with a company’s current needs. This is why the plan needs to be updated to reflect any organizational or staff changes, especially in companies that grow rapidly.
All the critical applications and procedures should be regularly tested and monitored to ensure they are disaster-ready. This is best achieved by assigning a specific task to the defined disaster recovery teams and training employees on disaster recovery best practices.
Closing Thoughts: IT Disaster Recovery Planning & Procedures
Given the dynamics of today’s business, occasional disruptions seem inevitable, no matter the company size. The significant disasters we have seen recently only enhance the sense of uncertainty and the need to protect critical data and applications.
While a disaster recovery checklist may have many goals, one of its most significant values is its ability to reassure company staff that they can handle any scenario and restore normal business operations. The suggestions given above are intended to guide your company up to this path.
If you’re currently considering available cloud disaster recovery options, take a look at phoenixNAP’s DRaaS solutions and contact us for any additional info.